Thursday, 9 October 2025
Episode #2 - Architecting the Agentic World


In this article, Murilo Cunha, CTO at dataroots, a Talan company, explores how organisations must rethink their technology architectures to embrace the rise of Agentic AI: systems capable of reasoning, planning, and acting autonomously.
He traces the evolution from generative AI to multi-agent intelligence, where large language models (LLMs) don’t just respond but execute and coordinate actions.
New frameworks like LangGraph, CrewAI, and SmolAgents, along with emerging standards such as MCP (Model Context Protocol) and A2A (Agent-to-Agent), are shaping this new ecosystem.
This transformation introduces major challenges in security, governance, and data architecture, requiring stronger human oversight and robust design principles.
Dataroots, a Talan company, and Talan supports organisations in building secure, interoperable, and trusted agentic systems — enabling them to fully harness the potential of autonomous, intelligent agents.
From AI Origins to Agents
AI Origins
Artificial Intelligence (AI) originally meant “anything that resembles human thinking”. Machine Learning (ML) focuses on finding data-driven statistical patterns. Generative AI (GenAI) technically means “AI that generates ‘something’”, and dates back at least as far as 2014 with Generative Adversarial Networks [1], popularly used to generate images. Large Language Models (LLMs) refer to models that can predict the next word in a sentence, after having analyzed massive datasets from the internet [2], significantly boosting the popularity of Generative AI.
The LLM architecture was first published in 2017 [3], but really “exploded” with the release of ChatGPT, in 2022 [4], bringing a simple interface to consumers around the world. Nowadays, the term “AI” is often (imprecisely) used as a synonym for Generative AI. For the remainder of this article, “AI” will be used interchangeably to GenAI (and specifically LLMs), unless otherwise specified. Definitions are important.
Generative AI
In the years since the release of ChatGPT, GenAI has been rapidly evolving. We can generally split LLMs into “regular/baseline” and “reasoning/thinking” models. Baseline models answer directly. Reasoning models may generate intermediate “scratchpad” steps (often hidden, sometimes referred to as “chain-of-thought" or “self-reflection") and use them to refine the final answer - akin to thinking out loud. Empirical results showed that reasoning models produce better results when it comes to reducing hallucinations [5].
Something as simple as counting the “R”s in “strawberry” may be a challenge for baseline models and better suited for reasoning ones [6]. On the other hand, you may observe that reasoning models are biased towards complex solutions, which prove unsuitable for simple tasks. In other words, reasoning models often “overthink” - even when counting letters correctly [7]. Selecting the right model for the right task becomes an increasingly important.
![Simple schematic of DeepSeek-R1 “Thinking” [8]](https://cellar-c2.services.clever-cloud.com/static.talan.com/s3fs-public/inline-images/1_1.png)
Some argue that the emergence of reasoning models is a clear signal that the capabilities of LLM architectures are reaching their full “intelligence” potential [9]. Whether through empirical results or subjective feeling, the pace of improvement as each model is released seems to slow down. And reasoning models were a result of looking for alternatives to the lack of fresh training data available. Nonetheless, models continue to advance.
LLMs continue to evolve in terms of capabilities. One pattern is to conform the output of the LLMs to a structured format. For example, to the question “which of my orders were not delivered on time?”, one would probably expect a list of delayed orders, where each item includes the seller, the product, quantity, ordered date and delivered date. While somewhat obvious, LLMs may struggle with this question, as they were designed to predict the next words and characters. That's where structured outputs come in. In practice, models predict the next characters as raw text, and then we use different tools to parse this text and see if it corresponds to format that we expect (in other words, we validate the output) [10]. This provides strong guarantees that the outcome corresponds to what we expect – that is, “dates” are actual dates (in the past), that “quantity” is an actual number, and so forth.
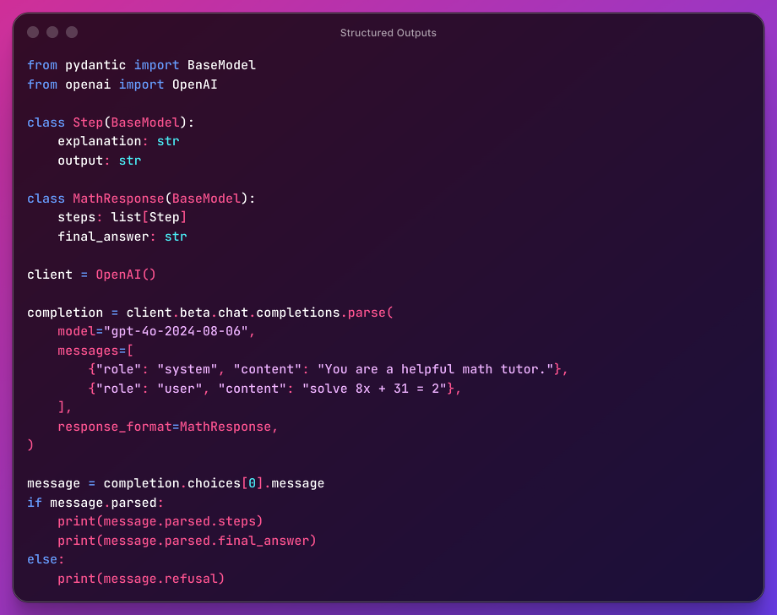
LLMs can also “call tools” - arbitrary code that is provided by the developer (via Python functions or in another programming language). In practice, when you ask a question, you may also provide a list of functions that are available to the model. Each function should be descriptive on what it does, what it expects as an input and what it returns as an output. With that the model can “decide” to request tool calls to the user depending on the conversation context.
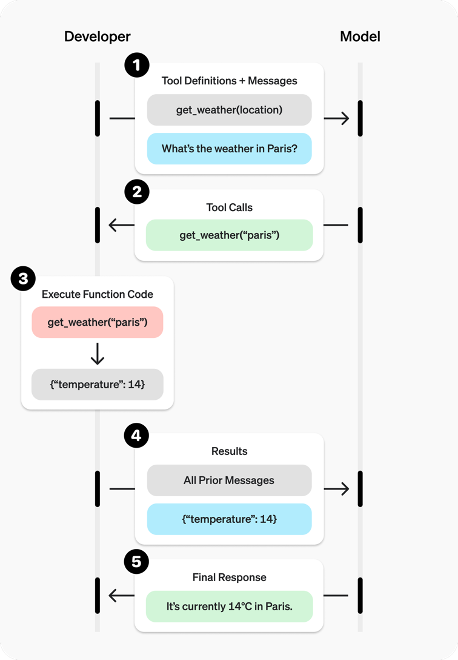
The developer executes the function calls and returns the results back (together with the conversation history). The question “what’s the weather in Paris?” would likely trigger the request “get_weather(‘Paris’)”. Interestingly, if we had asked “is it warmer in Brussels than in Paris?”, the model would (probably) “plan” two different function calls in parallel: “get_weather(‘Paris’)” and “get_weather(‘Brussels’)”. More than that, with the question “what’s the weather in the capital of France?” (with an additional “get_capital” function), the model would “know” to first request “get_capital(‘France’)” and later use the newly found information (Paris) to request “get_weather(‘Paris’)”. Simple pattern, but big implications: the model can plan, parallelize, and chain tool calls to solve complex tasks.
Agentic AI
With these functionalities, we have the foundation of Agentic AI. There are many different ways to define Agentic AI, but it can be generally referred to systems designed to operate autonomously, making decisions and taking actions to achieve a specific goal without constant human intervention. These systems often employ autonomy (agency), planning, reasoning, and learning capabilities to adapt to new situations and improve their performance over time.
Most of these properties are emergent of today’s LLMs (“natural” traits we observe as models scale in size). Meaning that given the right context (conversation history, prompts and tools) models already demonstrate many of these properties. From a developer point of view, the main difference is that Agentic systems do not have well defined end states. Agents are built by allowing LLMs to operate in an environment in a loop, with access to different tools, and allowing the system itself to determine when the task has been completed. In other words, “agents are models using tools in a loop” [12].
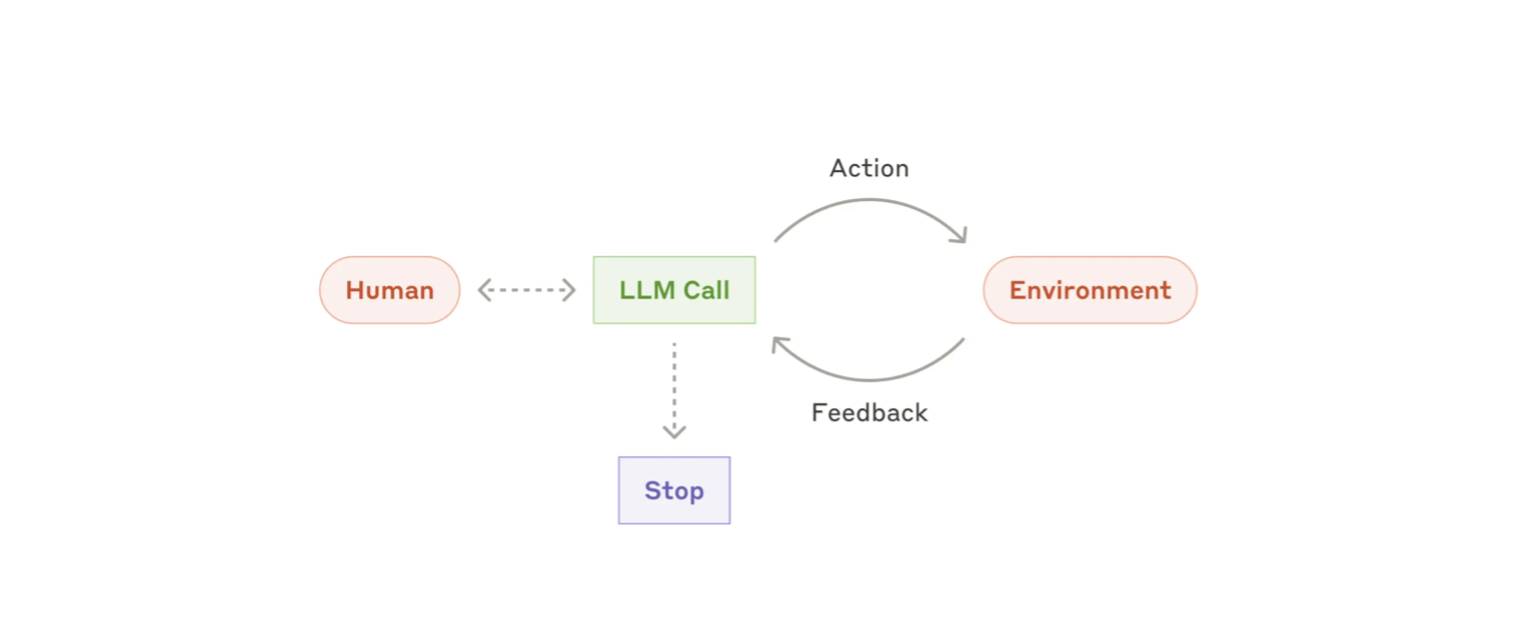
It’s important to note that the developer standpoint and the consumer standpoint are definitely related but may not necessarily mean the same thing. That is because agentic properties can also be achieved by establishing well defined workflows, in an “if-else-tree-style" fashion, with each response we can trigger another pre-defined reaction. Agentic experiences are different from agentic design patterns: one focuses on user experience, the other on system autonomy. One could build a travel planner agent by meticulously identifying question intents, determining states, links between these states and outputting pre-determined answers (i.e.: workflows with agentic experience), or by simply providing detailed prompts and tools without any state management (i.e.: agentic design pattern).
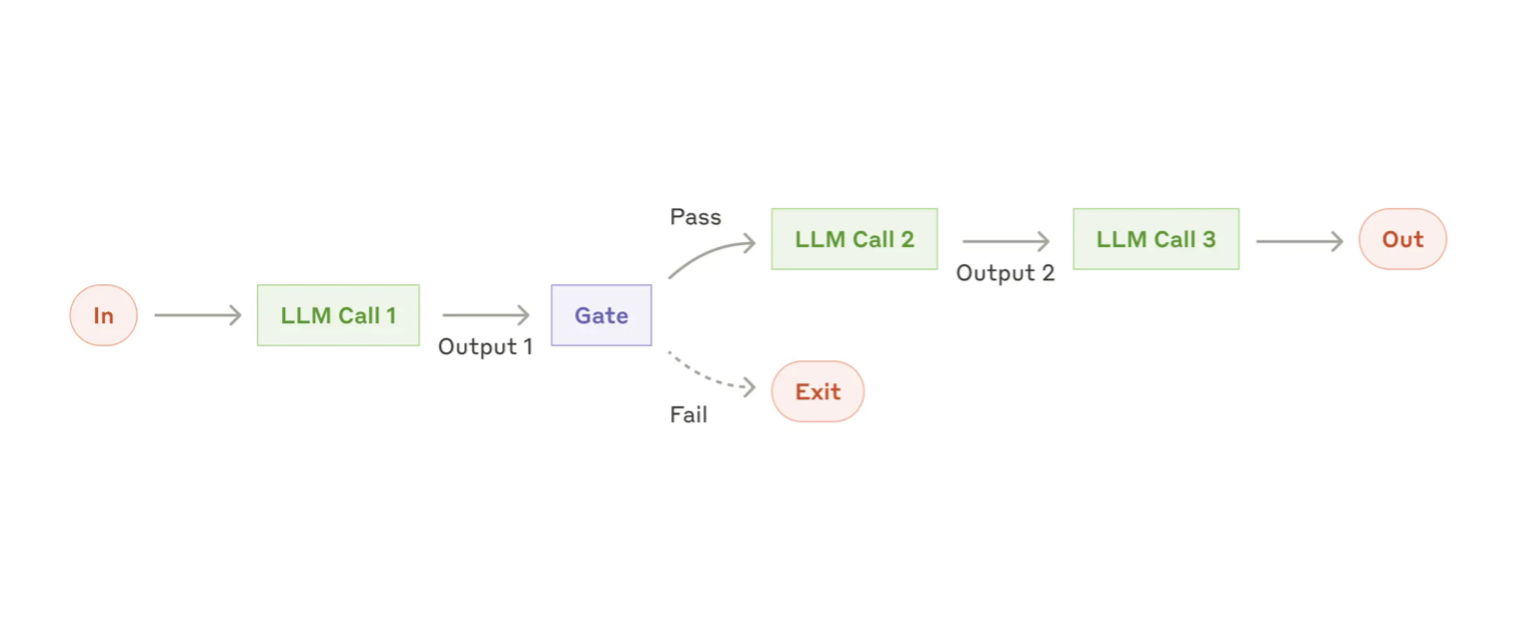
Workflows bring explainability and stronger guarantees on the desired output from the models, thus reducing the overall “risk” of the model hallucinating or generating unwanted responses. However, more complex use cases would require large and complex graphs, with conditional logic that may return to earlier nodes, managing the context required at each part of the graph. As development complexity grows, conversation quality suffers because we compel models to respond within rigid, pre-defined states that may not capture the full conversational context. This issue is compounded by complex graphs that blend business logic, prompts, and state management.
Agentic systems are valuable for tasks without pre-defined decision trees due to the open-ended nature of real-world problems, where requirements change, state spaces are large and complex, and user input is unpredictable. Attempting to hard code every scenario would lead to unmanageably large and incomplete decision graphs. Agentic systems, on the other hand, enable dynamic planning, allowing the model to “decide” which tools to use, when to conclude, or when to seek clarification. This adaptability is their key strength - their capacity to manage tasks where exhaustive workflow design is impractical or unfeasible.
How Agents Work
RAG and Agentic RAG
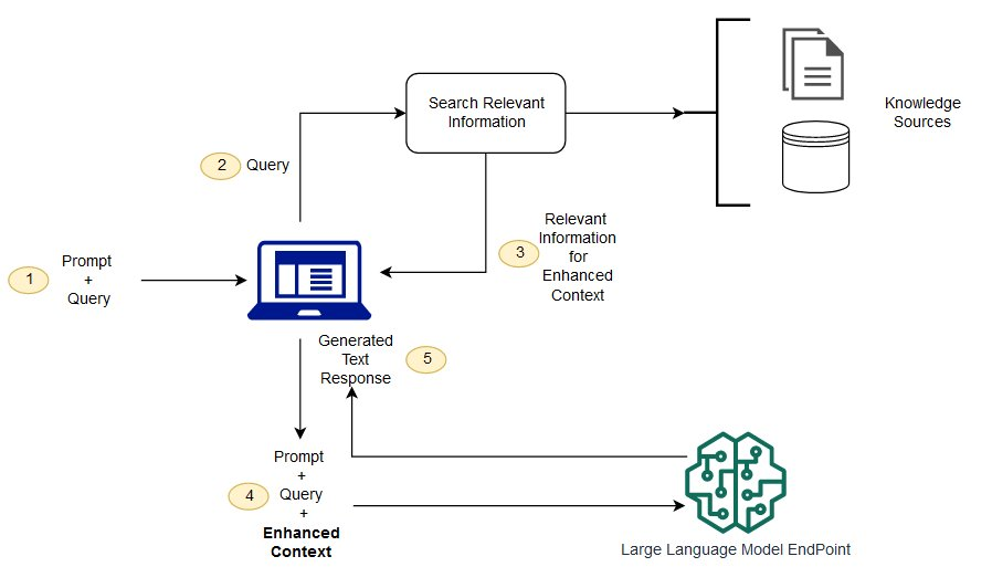
A very well established GenAI design pattern is Retrieval-Augmented Generation (RAG). With RAG, we ask a question to our LLM, but before submitting the question we enhance the conversation context with relevant information (identified through vector searches and embedding similarity – see more information here). With the question and the relevant information to provide an answer, we rely on the model to be able to accurately answer the question.
With Agentic RAG, the information retrieval becomes a tool available to the model, and the model is given agency to define when the task has been completed. Questions such as “What’s the average temperature in Paris during the month when the Tour de France ends?” can now be answered. First retrieving “When does the Tour de France end?” followed by “What’s the average temperature in Paris in July?”.
In theory, this approach scales - we can keep on adding tools to the same LLM and “hope” that it’ll always be able to make the right tool calls, with the right inputs. In practice, we find that agents often have a hard time handling large contexts (both for conversation history and available tools). It is found that for complex tasks, it is more efficient to split the work and responsibilities between different agents.
Multi-Agent systems
In multi-agent systems specialized agents collaborate and share context intelligently in order to accomplish a task. These different agents may have different models, conversation history, system prompt, available tools, among others. For example, a travel planning system may have different agents for finding the best flight tickets, accommodations, tourist attractions, and restaurant reservations. The main challenge becomes how to gracefully handover between one agent to another, while retaining the relative information required to perform the task, finding the right balance of including sufficient context to perform a task while also omitting the not-so-relevant information to get the best results (the “context engineering” problem).
Aside from agent touchpoints, there’s also the matter of execution order. As each agent performs a subtask, the context changes, which could also affect the downstream requirements to accomplish the task. Often, it may be better to run (sub)agents in sequence, waiting for a task to be done before dispatching a new one. Each (sub)agent may still have a different context, with a subset of the conversation history and different tools, while running sequentially. For highly independent subtasks, this is not necessary. Understanding how much context is required and identifying which tasks are truly independent (or to which extent) is yet another area where LLMs of today fall short and requires human assistance - one of the main developer tasks when architecting agents.
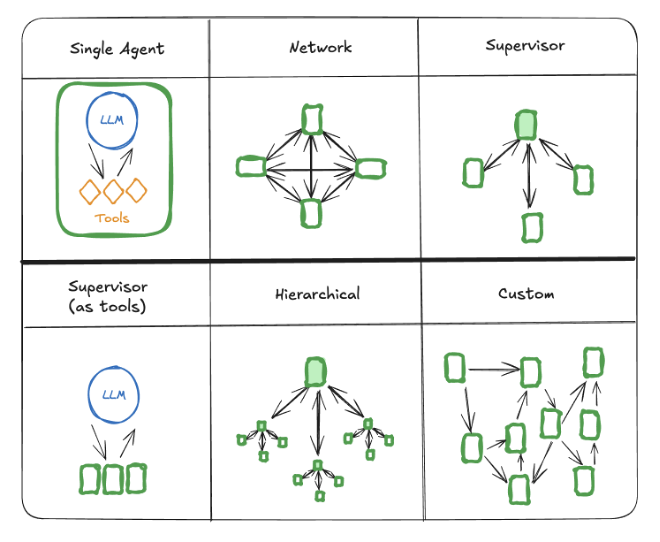
With the increasing complexity of developing these complex networks of agents, we also see the rise of many frameworks to support the development of multi-agent systems, including LangGraph, Pydantic AI, Crew AI, SmolAgents, among many others. Many of them have different approaches and a different development philosophy. And while LangGraph is the most popular at the time of writing (2025), it is still early to truly call any of them an “industry standard”. Especially as new standards are being defined and implemented by the different clients and frameworks (e.g.: MCP).
Standards & Security
Agent Protocols: MCP, A2A and ACP
Model Context Protocol (MCP) [ref], was developed by Anthropic as an open standard. It specifies how AI applications interact with external tools and systems. In other words, it makes it possible for users of (for example) ChatGPT to add arbitrary tools to be used by the LLM with no knowledge of the user interface of ChatGPT, Anthropic’s Claude, IDEs, among others. In this context, tools (which were Python functions) are transformed into servers, deployable either locally or remotely.
Today, MCP has momentum, and aims to establish itself as an industry standard for agent-tool communication, underpinned by a broad ecosystem of readily reusable servers.
The MCP protocol specifies how models interact with these tools, similar to how an OpenAPI (Swagger) specification outlines REST API usage. The MCP protocol enables (externally defined) tool use to models. This makes it easier to reuse and discover different tools to build novel AI agents and agentic workflows.
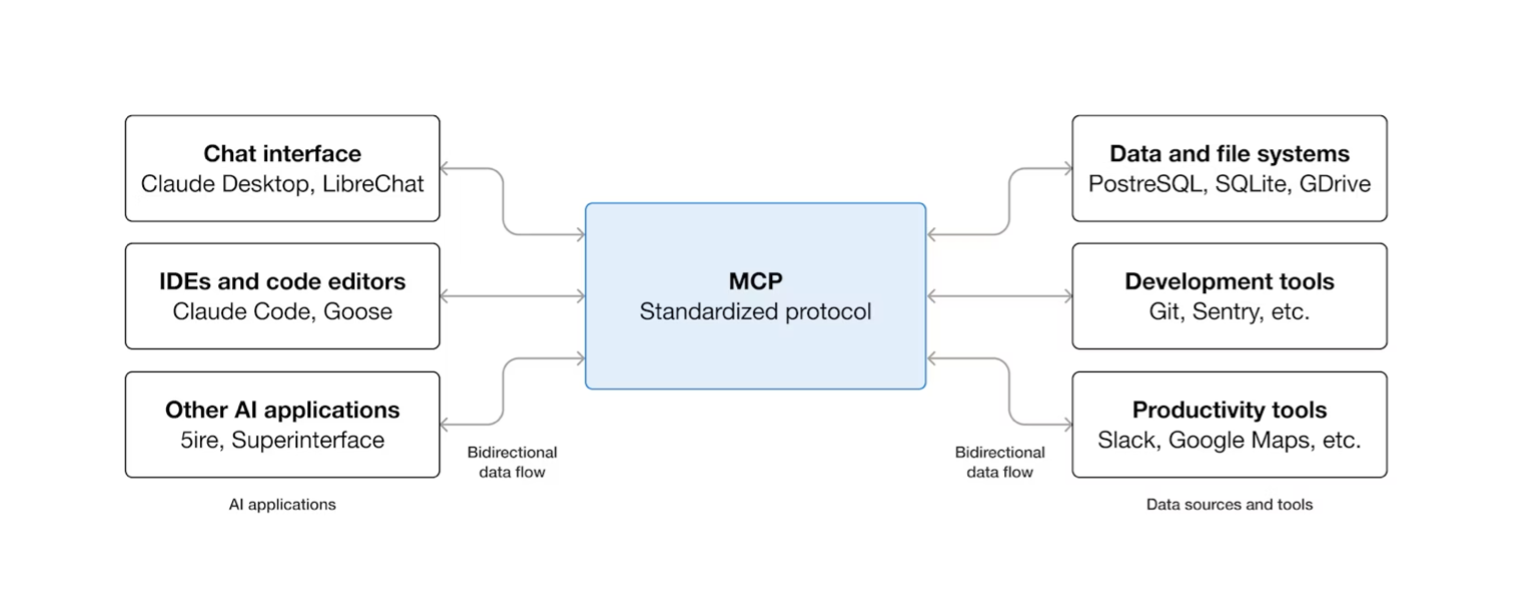
MCP tools can run arbitrary code. And (why not) also run LLMs and agents. A “summarizer” tool may employ an LLM to generate summaries. Therefore, MCPs can also be used to specify communications between agents, though not its original purpose, as it “forces” hierarchical communication between the two entities. Google's Agent2Agent (A2A) protocol offers a solution to key MCP limitations17. By establishing network-based communication, A2A allows agents to operate concurrently. This protocol, while currently mostly under research, sees an uptake in maturity with enterprise solutions and is worth monitoring.
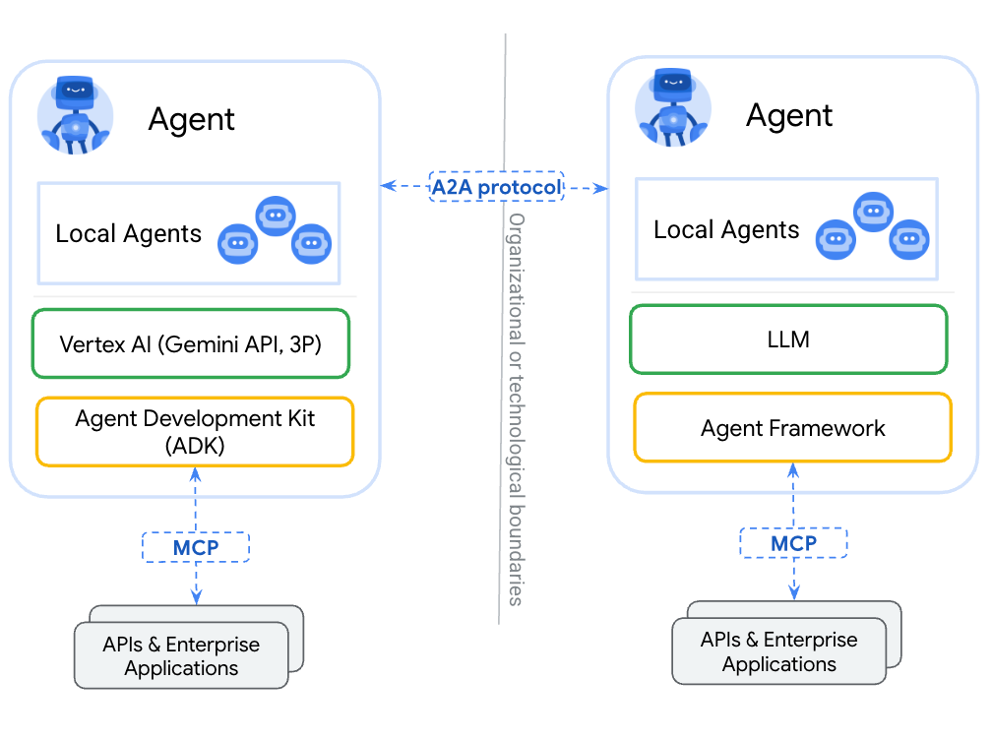
MCP and A2A sit next to many other agent-related protocols (though designed for different purposes and not as popular or widely implemented), including Agent Communication Protocol (ACP), developed by IBM [18] - later integrated into A2A [19], the Agent Client Protocol (ACP), developed by Zed [20], the Agentic Commerce Protocol (ACP), developed by OpenAI and Stripe [21] or equivalent protocol by Google - Agent Payments Protocol (AP2) [22]. The rise of different protocols is a strong signal on the importance and impact that AI Agents will bring, and how the main challenges lie in integrating different systems.
Data privacy and cybersecurity
Agentic AI introduces notable security concerns. The interaction data with AI models is frequently captured for retraining and fine-tuning, raising significant data privacy concerns and secrets leakage opportunities [23]. With the advent of AI as a service, AI engineers must also carefully consider the geographical location where data is stored and utilized to ensure strict legal compliance. Agentic AI, by definition, can interact with many different services via tool calling. These introduce many attack entry points for the agent via prompt injection [24], but also infrastructure failure points in case the wrong tool or arguments are called by the agent (sometimes in high volume). As MCP servers become more common and reusable, it’s important to vet servers before utilization, as many times that may mean having data moving outside the organization (and ensure it is treated responsibly) while also ensuring not a malicious code is being run in the MCP server.
Most of these risks are mitigated by carefully reviewing the agent's design, its tool-calling mechanisms, data handling practices, and the security of integrated services and servers. Agents may also perform under human oversight, effectively “asking for permission” before executing different tool calls. A robust monitoring solution for these agentic systems is crucial for auditability and reproducibility.
GenAI Ops
(Gen)AI reproducibility relies on mainly 2 components: models and context. That means that by versioning the different models, prompts, conversation history and available tools one should be able to, as best as possible, reproduce experiments. LLMs will always introduce randomness, but parameters (such as “temperature”, “top-p” and “seed” [25]) also influence how reproducible model results are. Reproducibility allows experiments to be performed and easily benchmarked, especially important as new models are constantly released, with more powerful capabilities (longer context, multi-modality, among others). If before with traditional ML models one could expect retraining and redeployment in months' time, today we see new foundational AI models released in weeks.
Parallel to performance checks, models should also undergo rigorous testing, to avoid regressions. Aside from unit and integration tests [26], AI systems must also undergo probabilistic testing – meaning that for the given inputs, models are expected to perform somewhat predictably (for example, with certain precision, recall, accuracy metrics). For generative AI specifically, the task becomes more complex as it’s not always clear what a correct or acceptable answer is. LLM testing is then generally split into “deterministic” and “LLM-as-a-judge" tests. “Deterministic" may validate the LLM output conforms to regular expressions (Regex) or include keywords. “LLM-as-a-judge"/“model-graded” refers to using LLMs to assess the answers of LLMs.
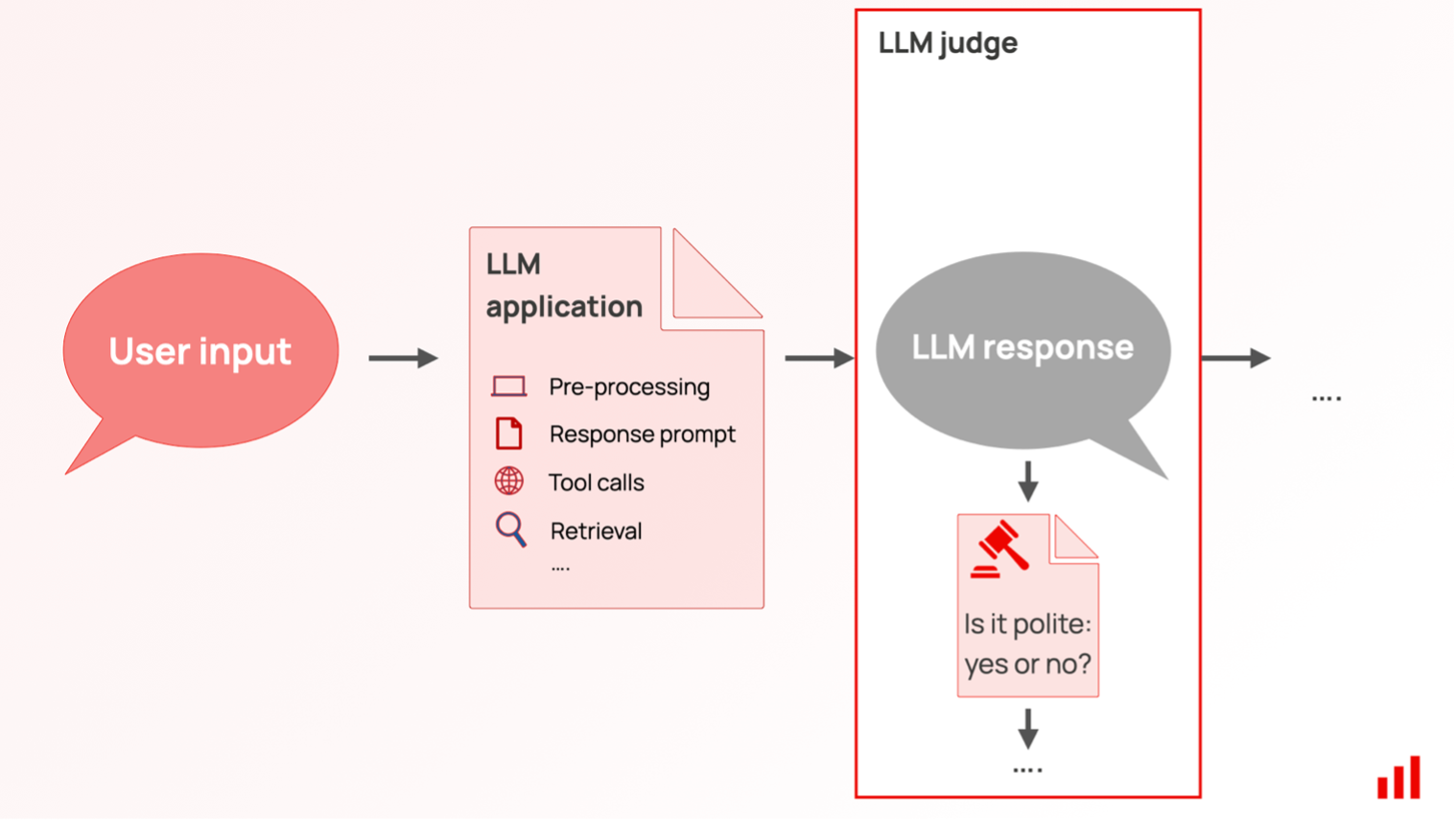
As the complexity of these systems grows, so do the monitoring requirements. Monitoring of agentic systems should keep track of model tokens used (for each model, if many), tool calls, their parameters, alongside costs for LLM tokens, and tool calls.
Agentic Data Platforms
As organizations increasingly adopt AI agents, the role of monitoring and governance in data platforms takes center stage. The proliferation of unstructured, agent-generated content introduces fresh challenges around data quality, traceability, and compliance. Robust tagging and other metadata to distinguish between human and LLM-generated data is becoming essential, as is source system tracking to preserve auditability. Data lineage - already important in traditional data engineering - gains new urgency when agents are empowered to create or modify information. Without proper observability, organizations risk quality degradation, unreliable queries, and hidden compliance liabilities. Even something as basic as schema documentation can determine whether an agent generates usable SQL queries or misleading results.
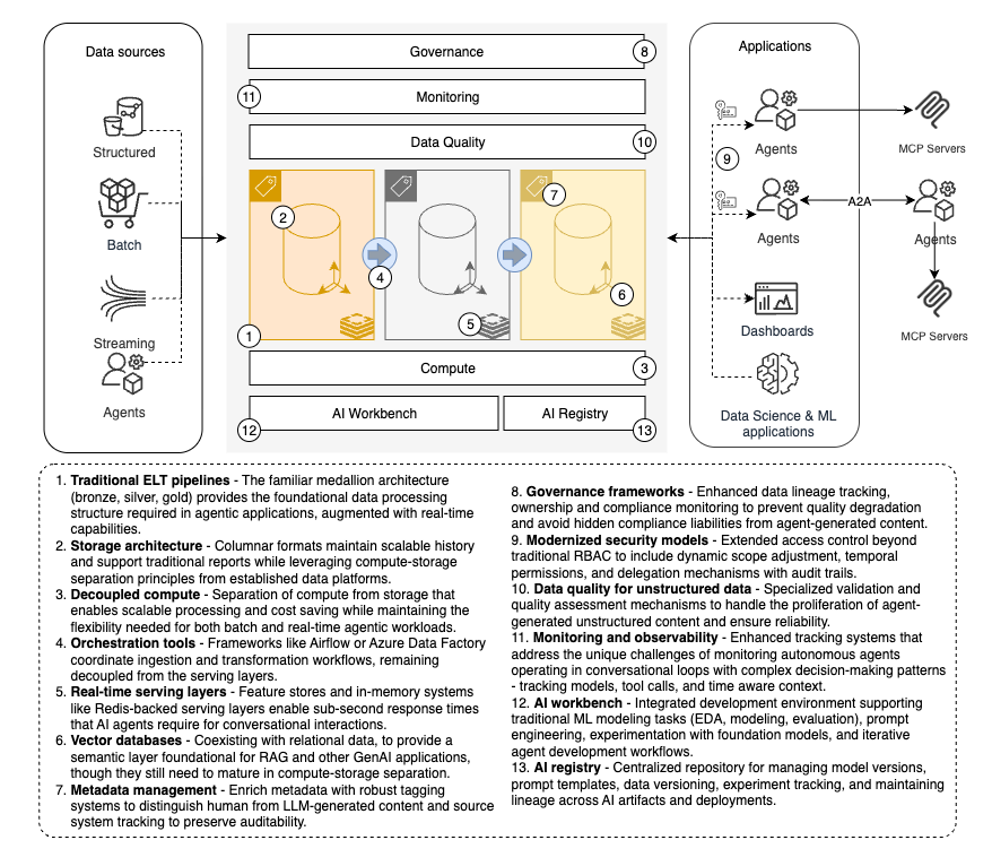
Under the hood, the modern data platform still relies on the familiar Extract, Load, Transform (ELT) pipeline with medallion layers (bronze, silver, gold) [28], the separation of compute from storage, and orchestration tools coordinating ingestion and transformation. BI dashboards and ML models consume data from structured layers, while ingestion frameworks like Airflow or Azure Data Factory remain decoupled. But for agentic workloads, traditional batch-oriented architectures are no longer enough. AI agents may operate in conversational loops where delays of even a few seconds undermine usability. This shift demands curated data in real-time extensions layered on top of established pipelines. For this, we can seek inspiration from a well-established MLOps solution.
Feature stores and other in-memory systems are emerging as critical enablers of these real-time requirements. Tools such as Hopsworks, which pair columnar storage with a Redis-like-backed serving layer, illustrate the hybrid model needed for agents: columnar formats maintain scalable history and support traditional reports, while row-based or in-memory stores handle queries like “what did Sarah do last week?” with sub-second response times. In this way, real-time and batch coexist, forming a bridge between durable analytics and interactive agent use cases.
The picture becomes more complex with vector databases, which provide a semantic layer on top of your data, foundational for many agentic and GenAI applications, such as retrieval-augmented generation (RAG). While platforms like Databricks Vector Search or Postgres (with pgvector) bring vector capabilities into mainstream ecosystems, they have yet to mature in terms of compute-storage separation - a standard feature in conventional data platforms. Scalability experiments, such as sidecar vector stores or S3-backed indexing [29], suggest the future direction. The indexing strategies chosen today will directly influence both the speed and quality of agent responses.
Agentic solutions on modern data platforms introduce nuanced security challenges that extend beyond traditional access control models. While role-based access control (RBAC) provides a foundation, autonomous agents require additional capabilities: dynamic scope adjustment based on task context, fine-grained temporal permissions that can escalate or de-escalate during execution, and delegation mechanisms that maintain audit trails while allowing agents to act with appropriate authority.
Current approaches like OAuth delegation scopes and service account impersonation provide partial solutions, but gaps remain in areas such as cross-system permission propagation, real-time permission revocation for long-running agent tasks, and maintaining user consent boundaries when agents make decisions that weren't explicitly pre-authorized. Attribute-based access control (ABAC) shows promise for encoding complex contextual rules (user intent, data sensitivity, time constraints), though implementation complexity and performance at scale remain significant hurdles. The core challenge isn't replacing existing security models but rather extending them to handle the temporal and contextual fluidity that characterizes autonomous agent behavior.
Extending data platforms for AI agents is not about discarding existing architectures but about augmenting them. Real-time serving layers, vector-aware storage, richer governance, and modernized security models all represent the next evolution. The platforms that succeed will be those that balance the reliability of traditional pipelines with the responsiveness, observability, and safety required in an agent-driven world.
The Agentic Transformation
As we move towards the agentic AI era, organizations must prepare for a fundamental shift in how AI systems operate autonomously to accomplish complex tasks.
The evolution from basic Generative AI models to tool-calling capabilities and sophisticated multi-agent systems represents a significant leap in agentic AI functionality, enabling systems that can make decisions, take actions, and adapt without constant human intervention.
While the technical foundations are rapidly maturing through standardized protocols like MCP and A2A, the real challenge lies in thoughtfully architecting systems that balance autonomy with security, performance with privacy, and innovation with governance. Success in this agentic world will require organizations to evolve their data platforms beyond traditional batch processing, embrace real-time architectures with vector databases and feature stores, and develop robust monitoring and testing practices that can manage the complexity of agent-driven workflows. Those that master this transition - building secure, scalable, and well-governed agentic infrastructures today - will be positioned to leverage the full potential of autonomous AI systems.
Book a meeting with me and Talan's AI team. We help our clients develop AI strategies that are both impactful and responsible.

Discover the Episode #1 of Talan's mini-series on agentic artificial intelligence
The new digitagentic interactions of brands and their customers. Agentic AI: How Autonomous AI Agents Are Transforming the B2B and B2C Customer Experience.
Sources
Murilo Cunha – CTO at dataroots, a Talan company
References
[1] Goodfellow, I., et al. “Generative Adversarial Nets”. Paper — 10 Jun 2014.
[2] Financial Times. “Generative AI exists because of the transformer”. Article - 12 Sep 2023.
[3] Vaswani, A., et al. “Attention is All You Need.” Paper — 12 Jun 2017.
[4] OpenAI. “Introducing ChatGPT.” Blog — Wed, 30 Nov 2022.
[5] Ziwei J., et al. “Towards Mitigating Hallucination in Large Language Models via Self-Reflection". Paper – 10 Oct 2023.
[6] Secwest. “The “Strawberry R Counting” Problem in LLMs: Causes and Solutions”. Article - 21 Mar 2025.
[7] Reddit. “DeepSeek-R1 Reasoning Passes the Strawberry Test”. Post - 21 Nov 2024.
[8] Language Models & Co. “The Illustrated DeepSeek R1.” Article - 30 Sep 2024.
[9] Reuters. “AI models’ slowdown spells end of gold rush era.” Article - 13 December 2024.
[10] OpenAI. “Introducing Structured Outputs in the API.” Blog Post — 6 August 2024.
[11] OpenAI. “Function calling.” Documentation — (accessed in Oct 2025).
[12] Simon Willison. “Agents are models using tools in a loop.” Blog Post — 22 May 2025.
[13] Anthropic. “Building Effective AI Agents.” Blog Post — 19 December 2024.
[14] Amazon Web Services. “What is RAG (Retrieval-Augmented Generation)?” Article — (accessed in Oct 2025).
[15] LangGraph. “Multi-Agent Architectures.” Documentation — (accessed in Oct 2025).
[16] Model Context Protocol (MCP). “What is the Model Context Protocol (MCP)?” Page — (accessed in Oct 2025).
[17] A2A Protocol. “What is A2A? - A2A and MCP” Documentation— (accessed in Oct 2025).
[18] Agent Communication Protocol. “Agent Communication Protocol.” Page — (accessed in Oct 2025).
[19] i-am-bee. “ACP Joins Forces with A2A Under the Linux Foundation” GitHub Discussion — 25 August 2025.
[20] Agent Client Protocol. “Introduction.” Overview — (accessed in Oct 2025).
[21] Agentic Commerce Protocol (ACP). “Agentic Commerce Protocol — An open standard for programmatic commerce flows.” Website — (accessed in Oct 2025).
[22] Agent Payments Protocol. “AP2 — Agent Payments Protocol.” Documentation — (accessed in Oct 2025).
[23] GitGuardian. “Yes, GitHub’s Copilot can Leak (Real) Secrets.” Blog Post — 27 March 2025.
[24] IBM. “What Is a Prompt Injection Attack?” Article — (accessed in Oct 2025).
[25] Google Cloud. “Experiment with parameter values.” Documentation — last updated 7 October 2025.
[26] CircleCI. “Unit testing vs integration testing.” Blog Post — 23 December 2024.
[27] Evidently AI. “LLM-as-a-judge: a complete guide to using LLMs for evaluations.” Article — 23 July 2025.
[28] Databricks. “What is a Medallion Architecture?” Glossary — (accessed in Oct 2025).
[29] Amazon Web Services. “Amazon S3 Vectors.” Feature Page — (accessed in Oct 2025).